Probabilidade Part-3 (Naive Bayes)
Naive Bayes
O Classificador Naive Bayes é um classificador probabilístico baseado na aplicação do teorema de Bayes com fortes suposições de independência (ingênuas) entre cada par de características.

Onde:
-
P(y | x1, ⋯, xj) é chamada de posterior e representa a probabilidade de uma observação pertencer à classe y, dadas as valores das j características, x1, ⋯, xj.
-
P(x1, …xj | y) é chamada de verossimilhança e representa a probabilidade das valores das características, x1, …, xj, dada a classe y de uma observação.
-
P(y) é chamada de priori e representa nossa crença na probabilidade da classe y antes de examinar os dados.
-
P(x1, …, xj) é chamada de probabilidade marginal.
Escolha da função
Para aplicar o modelo devemos antes analisar nossas variaveis preditoras antes.
- Quando as variaves preditoras são discretas, utilizamos a função MultinomialNB
- Quando as variaves preditoras são discretas e binarias, utilizamos a função BernoulliNB
- Quando as variaves preditoras são dados continuos, utilizamos a função GaussianNB
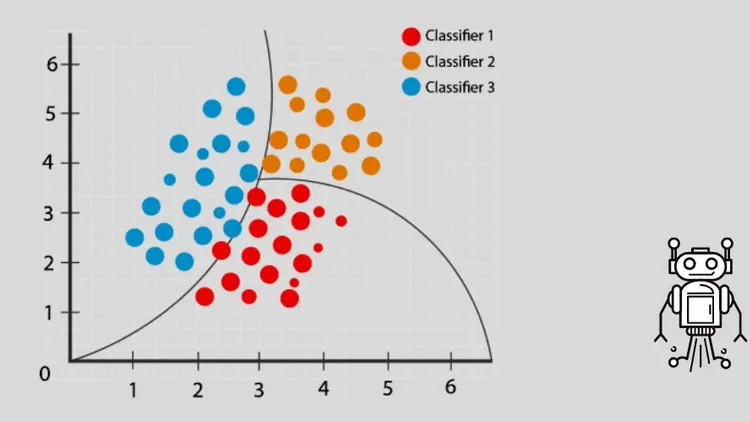
Conjunto de dados Íris
O conjunto de dados Íris é um dos conjuntos de dados mais populares em ciência de dados e aprendizado de máquina. Ele contém informações sobre 150 flores de íris, divididas em três espécies diferentes: Iris setosa, Iris versicolor e Iris virginica. Cada flor tem quatro características medidas em centímetros: comprimento da sépala, largura da sépala, comprimento da pétala e largura da pétala.
Exemplo de Aplicação
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
x = pd.DataFrame(iris.data, columns=[iris.feature_names])
y = pd.Series(iris.target)
x.head()
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
# Separando os dados de treino e de teste
X_train, X_test, Y_train, Y_test = train_test_split(x, y, test_size = 0.3, random_state = 67)
# Criação do modelo
model = GaussianNB()
model.fit(X_train, Y_train)
# Score
result = model.score(X_test, Y_test)
print(f"acurácia: {result:.2f}") # acurácia: 0.98